Bethany Warner, Junior Researcher, International Institute of Social History, Amsterdam //
On 14th to 18th July, the Alliance of Digital Humanities Organisations (ADHO) hosted its annual Digital Humanities conference at NOVA, Lisbon. The conference, with the theme of “Building Access and Accessibility, Open Science to all Citizens” explored a wide range of digital humanities themes, methodologies, and disciplines. Across 2 workshop days and 3 days of conference, researchers presented a huge diversity of topics and methodologies to approach humanities subject, from LLM integration in research workflows to image analysis in historical newspapers and more, conducted in a way which furthers the conference aims of furthering access, open science, and accessibility.

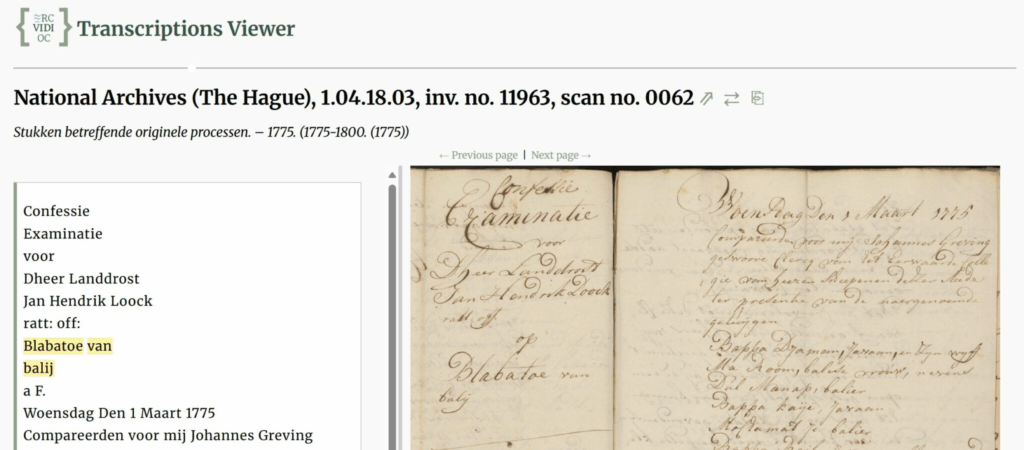
As part of the Voices project group, my work consists in creating handwritten text recognition (HTR) for colonial sources and slavery studies. This involves creating HTR models which make it possible to automatically transcribe historical documents—significantly advancing new avenues of historical research. At the conference, I had the opportunity to present our progress using Loghi, an open-source HTR tool developed at the KNAW. So far, we have successfully transcribed over half a million pages of colonial archival material, including from the Dutch East-India Company (VOC) archives. In addition, we have developed an HTR model for early modern Portuguese, with models for other languages currently underway. The resulting HTR makes the material searchable for the first time ever and opens the door for different kinds of computational and non-computational historical research.
HTR is a complex computational task due to language differences and the huge array of handwriting styles across time and space. This challenge has been taken up and explored by researchers across the world as machine learning models are rapidly improving. At the conference, I had the opportunity to engage with other presenters working on solutions to complex computational tasks such as abbreviations, multidirectional text and detecting authors by minute character differences. Many of these methods and tools being developed in an open-source manner, contributing both separately and collectively to efforts to make archival material more accessible. By using open-source tools, and by ultimately publishing our models, we hope to similarly contribute to this call.